Ansible's for loops
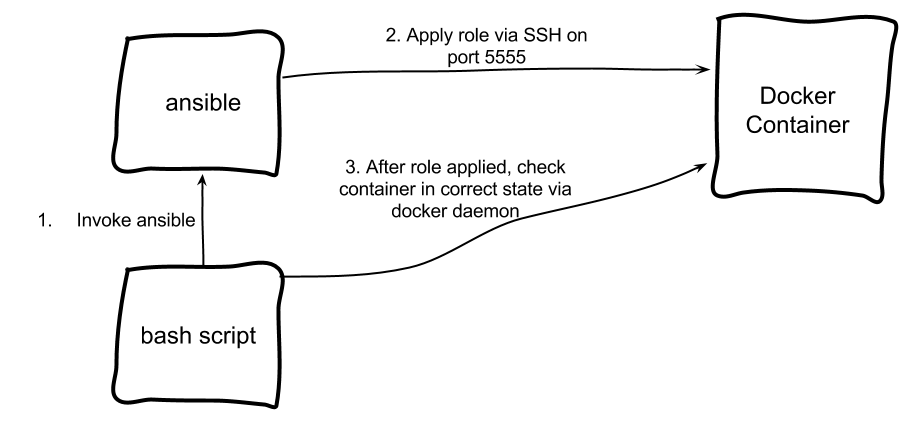
Recently, me and a team hit a big limitation with Ansible that really took me by surprise. For loops, can only iterate over a single task and not roles or playbooks . This post will discuss why it was a surprise, what we did to get around it and (briefly) what Ansible 2 introduces. Pre Ansible 2 The original issue really took me by surprise since the documentation on for loops showed a huge number of possibilities (including conditionals, looping over arrays etc etc) that suggested to me it was Turing-Complete and easily capable of meeting all our looping needs. So when I needed to assign a role multiple times (dynamically from a list) I was shocked to find that it couldn't be done. I'm not the only one who was caught out by this. See here , here and here . Why this wasn't supported really puzzled me. Some on my team concluded that it must be due to the way Ansible works internally and would perhaps require a lot of re-writing to support the feature. How